Porting your ML model as an onnxruntime WebAssembly application (pseudo-tutorial)
About a year ago, we needed to reproduce an experiment to detect cryptomalware. The experiment we replicated was MINOS, a neural network solution for the rapid detection of WebAssembly cryptomalware. The concept behind MINOS is to receive a binary bytestream as input, and then transform it into a 100x100 grayscale pixel image. Once the image is generated, a neural network provides a BENIGN or MALIGN classification over the 100x100 pixels as features. This method, previously used to detect malicious dll in Windows, was particularly novel in the context of WebAssembly. This is especially true since this method can classify binaries at an impressive speed. It is important to note that malware detection is a considerably difficult problem.
Speaking anecdotally, we reproduced to emphasize the impact of obfuscation in disrupting these types of methods, particularly for WebAssembly.
I received contact from colleagues regarding the sharing of our reproduction. At that time, we responded positively due to our advocacy for open-science and reproduction (we always provide a publicly available repository). We dispatched a Jupyter notebook illustrating the training and usage of the MINOS model. Additionally, we shared the h5 file. So, in theory, one could simply reopen the model and infer a new passed binary, as demonstrated in the following snippet.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
...
def load(self, model_name="minos.h5"):
self.model = keras.models.load_model(model_name)
...
def predict(self, data):
"""
Given dataframe, uses the model to
predict the labels
Parameters
----------
data : pandas.DataFrame
The dataset frame containing the instances to be predicted
"""
X, _ = self.preprocess(data)
p = self.model.predict(X)
d = pd.DataFrame(p, columns=MINOS.classes)
return d
However, there was something in my thoughts: there must exist a more efficient method to disseminate, at the very least, the inference process. Using the provided code snippet above, you can establish your own flask server API and expedite the inference process significantly. This method, however, suffers from inadequate scalability. What if the goal is to deploy this in a production environment? Several solutions exist that address the automatic scaling of such a service. Yet, my interest lay in investigating a zero-cost solution. Is it possible to execute the model for inference directly in the browser?
Imagine a design-sketch website that uses AI and purely migrates the AI inferring to your browser.
A solution like this could potentially solve many problems.
- Users will not need to install anything (no
pip install -r requirements.txt, thanks). Users can simply open a webpage and execute the inference with their browser. After all, a web browser is essentially a virtual machine. - This solution is cost-effective; it could be deployed on a static webpage, bypassing the need for a machine learning inference pipeline infrastructure. Consider, for instance, that the demo page is hosted by GitHub static pages system.
- In addition, it would not need internet. Once the webpage is completely loaded, it would run without making external query. Imagine a PWA application with this.
- Last but not least, by ensuring that data remains confined to the browser during the inference process, this method not only enhances safety but also contributes significantly to safeguarding user privacy.
The subsequent text describes how I succeeded in doing so. However, if you want to try it immediately, you may access the demo. Here, https://github.com/Jacarte/ralph, you can find the repository.
The how
My initial attempt focused on discovering a method to directly execute the h5 file. Unfortunately, this effort proved unsuccessful as I was unable to locate a viable solution (or one that I liked it). Yet, during the process, I learned about onnx.
ONNX is an open format built to represent machine learning models. ONNX defines a common set of operators - the building blocks of machine learning and deep learning models - and a common file format to enable AI developers to use models with a variety of frameworks, tools, runtimes, and compilers
The PyTorch team at Facebook originally developed ONNX under the name Toffee. In September 2017, Facebook and Microsoft announced a renaming of Toffee to ONNX. The community also introduced a method to deploy machine learning models using this format. The onxxruntime project, primarily implemented in C++, proves to be exceptionally fast when using an ONNX file for inference. Most significantly, the onxxruntime can be compiled to WebAssembly. WebAssembly serves as the ideal solution for porting such projects to the web. It surpasses JavaScript in performance within the browser, notably on mobile devices. The Emscripten compiler is used to port the onnxruntime to WebAssembly. In essence, I just needed to find a method to convert the h5 file of the model to an ONNX file, and then employ the onxxruntime to execute it in the browser.
It requires two lines of Python code to generate an ONNX file from a Keras model.
1
2
import tf2onnx
model_proto, _ = tf2onnx.convert.from_keras(self.model, opset=13, output_path=model_name)
I had all necessary components: a runtime ported to Wasm to load and use an ML model. I only required a few lines of JavaScript to ensure the MVP. However, the issue with this current solution is its distribution. I would inevitably end up disseminating the model and the inferring runtime as separate artifacts - the Wasm runtime on one side and the onnx file model on the other. Besides, in any case the input needs to be turned into a “grayscale” image before feeding the model. To solve this, I chose to package all into a single WebAssembly file: the model, the runtime and the preprocessing of the input binary as a grayscale image. Ideally, the application would contain a single entry point - the vector used as input for inferring, in our case, the bytestream of potential malware.
Disclaimer: The onnxruntime project provides tutorials aimed at achieving the goal of porting inference to the web. Yet, note that in the existing tutorials, the data preprocessing is not handled within the WebAssembly binary. The key distinction in my approach lies in precisely encapsulating all components within the same Wasm program, which is expected to result in improved performance and efficiency.
To the best of my knowledge, Rust stands as the premier toolchain for compiling WebAssembly binaries. Though Emscripten is great, it is afflicted by typical C/C++ project issues, e.g., the configuration for compiling C/C++ projects is inherently challenging. Fortunately, a solution to this problem exists in the form of onnxruntime bindings in Rust. The ort project serves as a Rust wrapper for onnxruntime projects. Using it allows us to produce a single WebAssembly file that includes the onnx model, the runtime and the preprocessing logic of the input.
The following snippet illustrates the application’s code.
The application embeds the model on its third line of code, achieved simply by injecting the model file as pure bytes.
The init_model function loads the model and assembles the inference pipeline.
The infer function takes a pointer in memory and the size of the byestream, converts it into an image, and feeds the model to obtain the classification.
Notice this code is just an MVP. I am sure there exist better ways to implement such code. To begin with, the
unwraping is definitely a bad practice.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
# Cargo.toml
[package]
name = "wasm_wrapper"
version = "0.1.0"
edition = "2021"
description = "Simple wasm wrapper for an ONNX model"
[lib]
crate-type = ["cdylib"]
[dependencies]
ort = "2.0.0-alpha.2"
image = "0.24.7"
ndarray = "0.15"
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
// main.rs
use ort::{inputs, GraphOptimizationLevel, Session, SessionOutputs};
use ndarray::{Array, Array1};
// Embed the model here
static MODEL: &[u8] = include_bytes!("model.onnx");
// Load the model in the start function
static mut model: Option<ort::Session> = None;
// FIXME: this should be optimized with Wizer, in order to avoid the loading of the data on every fresh
// spawn of a potential wasm32-wasi module :)
#[no_mangle]
pub extern "C" fn init_model(){
unsafe {
println!("Init model...!");
model = Some(
ort::Session::builder().unwrap()
.with_optimization_level(GraphOptimizationLevel::Level3).unwrap()
// Sadly we cannot add several threads here due to that this will be loaded in a single Wasm thread
.with_model_from_memory(&MODEL).unwrap()
);
println!("Model ready...!");
}
}
#[no_mangle]
pub extern "C" fn infer(wasm_ptr: *const u8, size: usize) -> i32 {
// Turn the bytes into a vector of 100x100 integers
let wasm_bytes = unsafe { std::slice::from_raw_parts(wasm_ptr, size) };
let sqrt = (wasm_bytes.len() as f64).sqrt() as usize;
if sqrt == 0 {
println!("Invalid input len 0");
return -1;
}
// Create an image from the bytes using sqrt*sqrt size
// It is grayscale, so we can use a single channel
let img = image::GrayImage::from_raw(sqrt as u32, sqrt as u32, wasm_bytes.to_vec()).unwrap();
// Now scale it to 100x100
let img = image::imageops::resize(&img, 100, 100, image::imageops::FilterType::Nearest);
// Convert it to a vector of floats
let img = img.into_raw().iter().map(|x| *x as f32).collect::<Vec<f32>>();
// Call the inferring
if unsafe { model.is_none() } {
println!("Model not initialized");
return -1;
}
println!("Feeding input");
let mut input = Array::zeros((1, 100*100));
input.assign(&Array::from_shape_vec((1, 100*100), img).unwrap());
let input = inputs!["reshape_input" => input.view()].unwrap();
let modelref = unsafe { model.as_ref().unwrap() };
let output = modelref.run(input);
match output {
Ok(output) => {
let output = output["dense"].extract_tensor::<f32>().unwrap()
.view()
.t() // transpose
.into_owned();
let output = output.iter().map(|x| *x as f64).collect::<Vec<f64>>();
if output[0] > 0.5 {
return 0;
} else {
return 1;
}
},
Err(e) => {
println!("Error: {:?}", e);
return -1;
}
}
}
I compiled the application with the command below. This command establishes several parameters for Emscripten and constructs the application in the wasm32-unknown-emscripten architecture.
1
EMCC_CFLAGS="-sERROR_ON_UNDEFINED_SYMBOLS=0 -s TOTAL_STACK=32MB -s ASSERTIONS=2 -s TOTAL_MEMORY=256MB -s ALLOW_MEMORY_GROWTH=1 -sEXPORTED_FUNCTIONS=\"['_malloc', '_infer', '_init_model']\" --minify 0 -Os -sMODULARIZE=1 -o dist/model.mjs" cargo build --target=wasm32-unknown-emscripten
As a result we have the following two files as the application:
1
2
9.5Mb model.wasm
200Kb model.mjs
To use them in a webpage, I needed just a few lines of code.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
<script type="module">
import model from './model.mjs';
model().then(r => {
r._init_model();
// Set the callback for loading a file in the form
document.getElementById('file').addEventListener('change', function(e) {
var file = e.target.files[0];
if (!file) {
return;
}
var reader = new FileReader();
reader.onload = function(e) {
var contents = e.target.result;
var content_bytes = new Uint8Array(contents);
// We need to send a ptr
var input_ptr = r._malloc(content_bytes.length);
console.log(input_ptr);
r.HEAPU8.set(content_bytes, input_ptr);
// write WASM memory calling the set method for the Uint8Array
let now = performance.now();
let result = r._infer(input_ptr, content_bytes.length);
r._free(input_ptr);
result = result? "BENIGN": "MALICIOUS";
document.getElementById('val').innerHTML = result;
};
reader.readAsArrayBuffer(file);
});
}).catch(r => {
})
</script>
See the live demo here. This represents zero-cost ML model deployment running in your browser. The performance numbers are quite impressive. On my computer, it takes nearly 30ms to infer from a 2Mb file. Please note, this time not only includes the inference but also the conversion of the binary into a grayscale image (check the gif below).
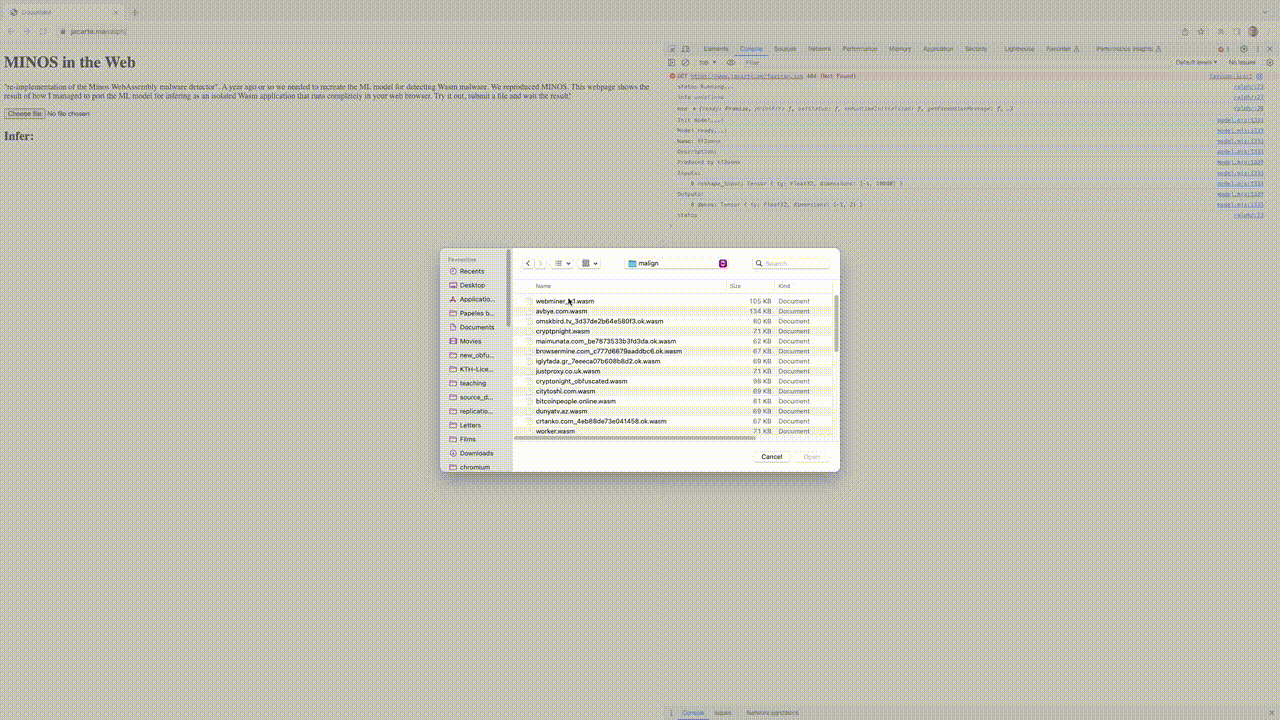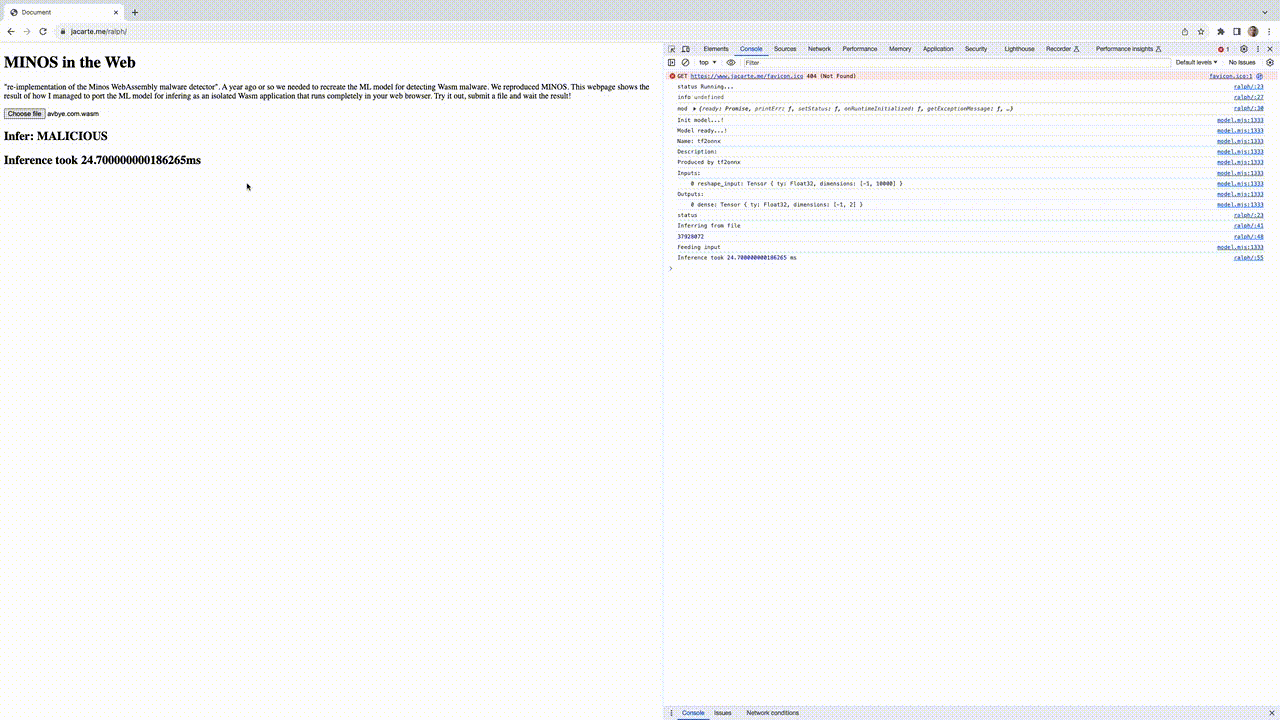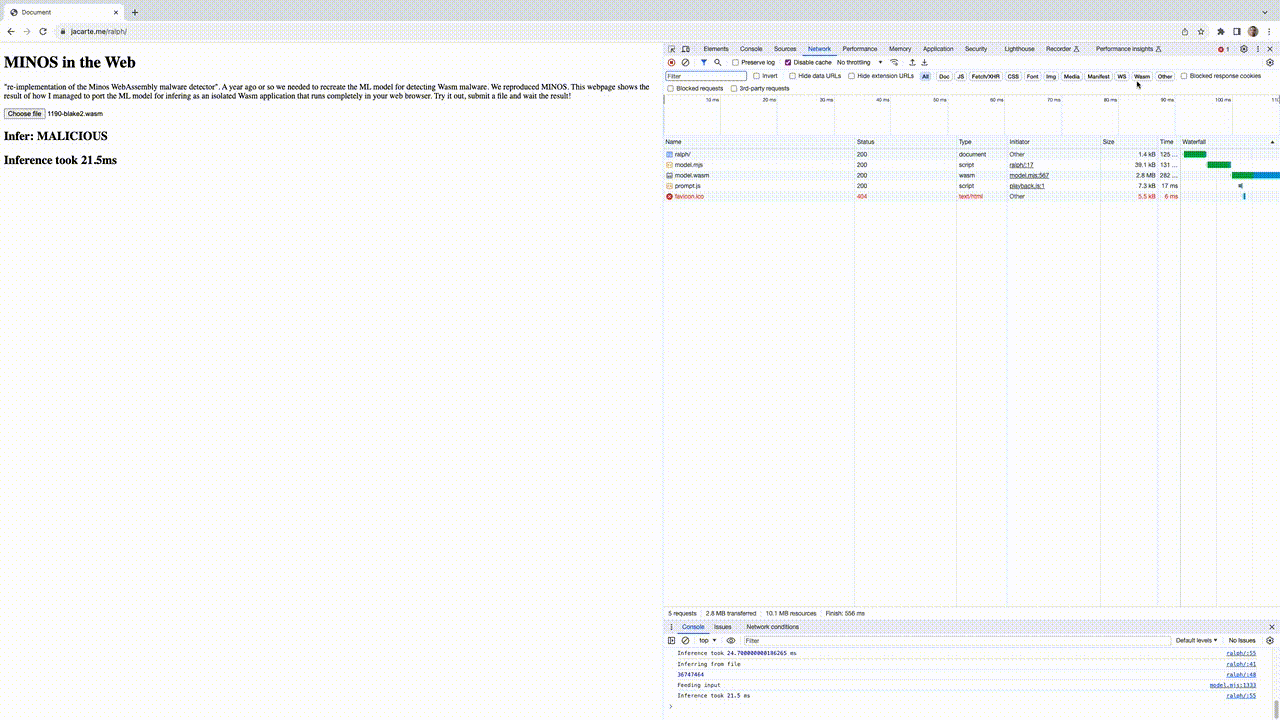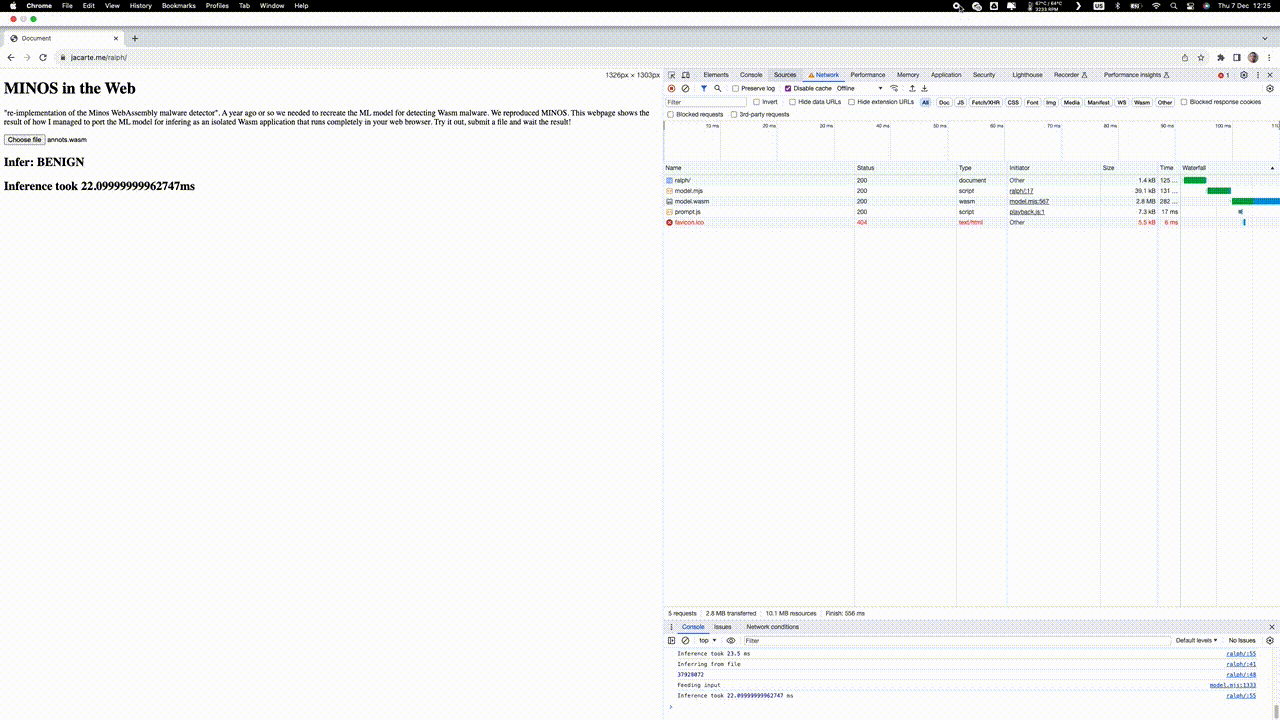
Discussion
I avoid drawing comparisons between this approach and others. I leave this task to you. In lieu of this, I will outline two specific points I have observed throughout the process of implementing this.
First, it must be acknowledged that this method is not foolproof. If the model size is on the larger side, a webpage may require several minutes simply to render the model available for execution. However, the capability of the Rust wrapper to compile to Wasm makes it an apt choice for Cloudflare workers or Fastly Edge@Compute. This allows for the transfer of inference to the Edge. Such a transition boasts additional benefits, including the automatic management of scalability. It’s worth noting that launching a Wasm program in the Edge takes nothing more than a few nanoseconds.
Second, the necessity for manual implementation of the interaction with the host browser is a notable drawback. Take, for instance, the infer function in the Rust code, which requires a pointer.
Passing this pointer takes 3 lines of JavaScript code at least (take a look to the last snippet).
Ideally, it should only need to handle a byte array type, something akin to wasm: &[u8]. There exists a solution: wasm-bindgen. However, this only functions for the wasm32-wasi architecture. Regrettably, the onnxruntime has a significant dependency on Emscripten, i.e., needing compilation via Emscripten. This presents further issues with potential Edge deployment, as Wasm-WASI programs are typically more suitable for running in the Edge. On a positive note, people are working on a promising alternative to load ML models and operate them for inferring in WebAssembly, the WASI-NN proposal.